Semantic Chunking
Or, more simply: how smart, customized RAG solutions deliver better answers
It probably won’t surprise anyone that a consultancy focused on semantic technologies believes that semantic decomposition — or the more headline-friendly term semantic chunking — really matters. Whether you’re building a generative AI assistant or a more traditional analytics workflow, better decisions usually come down to having the right information at the right moment. That might mean real-time sensor data driving an automated process, or it might mean helping a human answer a detailed question about a product, regulation, or technical system. In either case, identifying the relevant context quickly and accurately is what makes the answer useful.
For small or tightly scoped knowledge bases, this isn’t hard. A simple chatbot can scan most or all of the available material and produce a reasonable response. But once you’re dealing with hundreds or thousands of pages — manuals, specifications, discussions, updates, and historical notes — brute-force approaches stop working. You can’t realistically pass all that material to an LLM every time, and retraining a custom model is expensive, slow, and often impractical when the data is changing.
This is exactly why Retrieval-Augmented Generation (RAG) has become so popular. Instead of training the model on everything, you retrieve just the most relevant context and use that to support generation. But this is also where many RAG systems start to struggle. If your documents are simply chopped into uniform blocks and indexed, the retrieved “chunks” can end up being a kind of word salad — loosely related text that looks relevant on the surface but doesn’t actually answer the question being asked.
That’s where semantic chunking comes in. On the Cognosa AI-as-a-Service platform, we load data in a way that tries to preserve meaning, not just token counts. The goal is to capture complete ideas — instructions, definitions, explanations, constraints — at a level of detail that makes sense for each source. A 300-page user manual needs to be handled very differently from a collection of recipes or short biographies. Product catalogs introduce their own challenges, especially when many items share similar attributes and options and the system must not mix them up.
You’ll often hear people talk about different “chunking strategies,” and a quick search will turn up plenty of debates about which approach is best. But when you step back, most of these discussions are really circling the same principle: keep meaningful, coherent information together, and don’t break associations that matter. The specifics vary by use case and data source, but the underlying goal is the same — make it easy for the system to retrieve context that actually helps answer the question.
There are, of course, many ways to implement this. You can describe semantic chunking in algorithmic terms, or focus on whether the parsing is done with LLMs, traditional NLP tools, rule-based approaches, or some hybrid of all three. Those choices matter for cost, performance, and reliability, but they’re ultimately tactical. The strategy is not “use an LLM” or “use a specific algorithm”; the strategy is to organize knowledge in a way that consistently supports high-quality answers.
In the real world, data is rarely neat or homogeneous. A collection of journal articles or a large email archive is about as simple as it gets. Most enterprise knowledge bases are far messier: user manuals, standards and regulations, technical specifications, customer correspondence, chat logs, spreadsheets, diagrams, tables, and scanned documents all mixed together. Making this usable requires organizing content based on what it means and how it relates to likely questions — not just where it appears in a file.
At CogWrite, we’ve built and refined RAG collections using a range of tools and techniques across many projects. We maintain a growing library of ingestion routines and have created vector databases for different types of domain-specific AI solutions. This allows us to adapt quickly while still tailoring the approach to the data and the problem at hand.
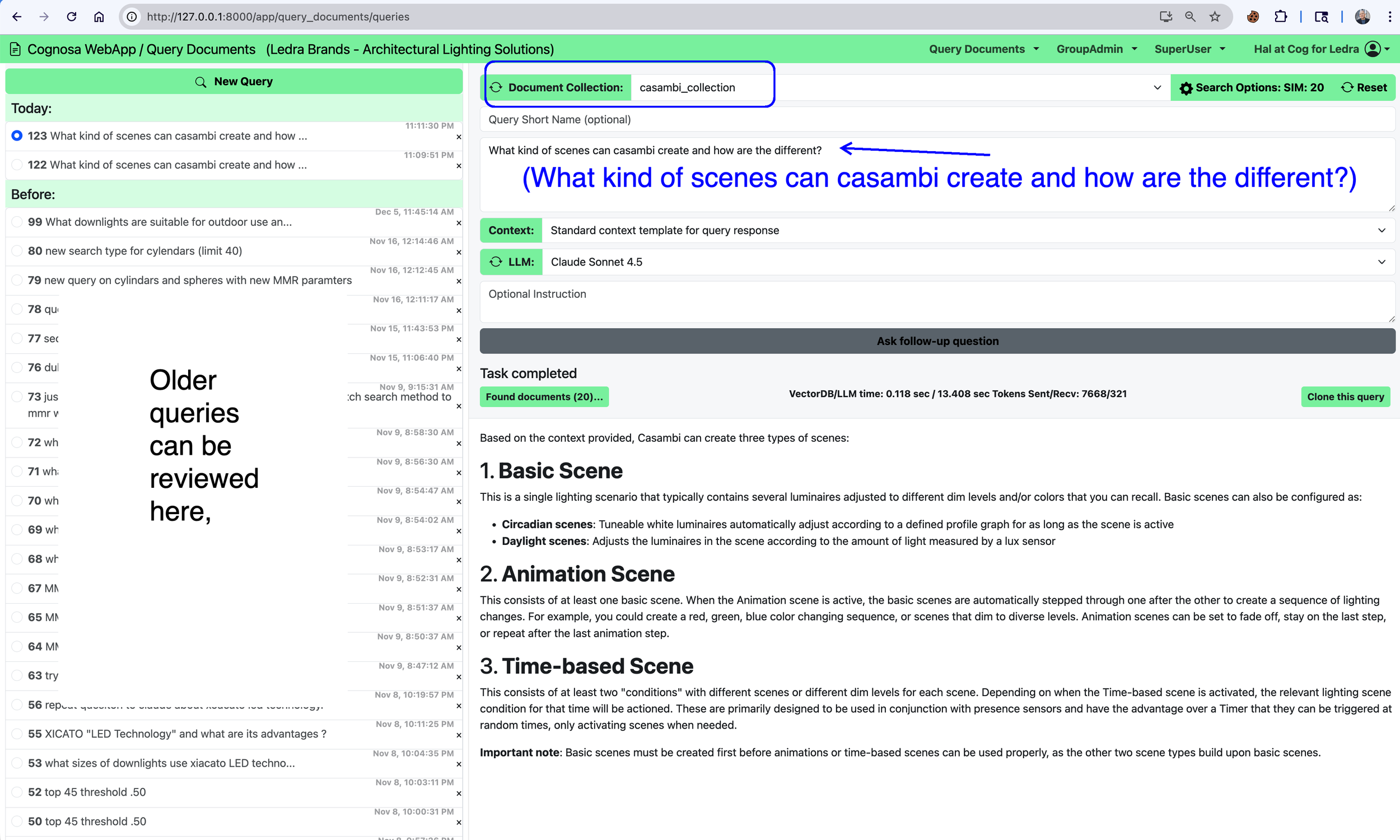
One example is our work around Casambi, an open-source, low-energy Bluetooth lighting control protocol. There’s a wealth of publicly available material about Casambi — documentation, specifications, guides, presentations, and discussions — but it exists in many formats and levels of detail. We built a Casambi document collection specifically to support a question-and-answer workflow, and it has become one of our internal testbeds for experimenting with more sophisticated semantic chunking techniques and retrieval strategies.
A sample query and response from that system is shown below.
A simple query about a complext progocol implemented around the world for high quality industryial lighting control and management.