The Build vs. Buy Question Nobody Frames Correctly
The conversation usually goes like this. A vendor pitches a polished AI solution. Someone in the room says, "We could probably build this ourselves." Someone else asks what it would cost. Someone else mentions control and customization. Within ten minutes, the meeting has turned into a debate about engineering capacity and licensing models, and nobody has touched the question that actually matters.

My attempt at visualizing my thesis — but like a joke you have to explain, maybe a bit obscure? The visual argument here is one of inversion: the commodity is being lovingly hand-crafted, and the differentiator is being assembled like fast food. Exactly the mistake the article describes - building what you should buy, and buying what you should build.
That question isn't whether you should build or buy. It's whether the problem in front of you is generic or proprietary. Most build-vs-buy decisions go wrong because the framing is wrong from the start.
The Wrong Question
Cost and control sound like reasonable axes. They aren't, at least not as the primary frame.
Cost is misleading because it pretends the build option has a stable price tag. It doesn't. The build path's true cost is the engineering opportunity cost over a multi-year horizon plus the ongoing maintenance burden plus the risk of organizational dependency on whoever wrote the code. Most internal estimates only count the first six weeks, which is why so many "we'll just build it" projects end up costing five times more than the buy option they rejected.
Control is misleading because organizations rarely need it for the things they think they do. Control matters where your edge lives. Everywhere else, control is just a tax — you're spending engineering attention defending an internal version of something you could have rented for less than the cost of one engineer's quarter.
When cost and control are the dominant frame, organizations consistently buy what they should have built and build what they should have bought. Both mistakes are expensive in different ways.
The Right Question
The cleaner frame is this: is the problem you're solving generic or proprietary?
A generic problem is one that looks broadly the same across organizations in your space. Email parsing, document classification, common transcription, off-the-shelf NLP, standard recommendation flows. These are problems where your competitors have the same shape of need, the same shape of data, and the same shape of acceptable solution. Your edge doesn't come from solving them better. Your edge comes from somewhere else, and these systems just need to work reliably and cheaply.
A proprietary problem is one that depends on data only you have, judgments only your organization makes, or workflows that don't translate to anyone else's environment. The shape of the answer depends on the shape of your business. A vendor walking in cold would need months just to understand the context, and even then they'd be implementing your team's expertise rather than bringing their own.
Generic problems should almost always be bought. Proprietary problems usually have to be built, at least the parts where the proprietary nature actually lives.
Three Tests for "Generic"
When I'm sitting with a team trying to make this call, I usually run three tests.
Could a vendor sell this same product to ten of your competitors? If the answer is yes, you're looking at a generic problem. The vendor's investment in the product is amortized across that whole market, which is why their version will almost always be better and cheaper than what you can build internally for your single use case.
Is the data largely standardized across your industry? Standard formats, standard schemas, standard meanings. If the data isn't proprietary in a meaningful way, the system processing it usually shouldn't be either. You're not getting an advantage from a custom build; you're just paying to maintain something a third party already maintains.
Does your competitive edge come from the solution itself, or from how it interacts with your proprietary data and processes? This is the test that matters most. If the edge is in the solution, you have to own it. If the edge is in everything around the solution, the solution is a commodity input, and commodity inputs should be bought.
If the answers point to generic, buy. The discipline is to actually buy, not to talk yourself into building because your team finds the problem interesting.
Three Tests for "Proprietary"
The same three tests, run from the other direction.
Does the problem depend on data only you have? If the system's value comes from working with your specific corpus, your specific operational logs, your specific customer interactions, then no vendor can match what an internal team can build. The data is the moat, and the system has to be designed around how the moat actually behaves.
Does the answer depend on workflows, definitions, or judgments specific to your organization? A claim severity classifier that uses your underwriters' judgment patterns isn't the same product as a generic claims classifier. Neither is a recommendation system tuned to your pricing logic, your inventory dynamics, and your specific customer behaviour. These systems encode institutional knowledge. Vendors can't sell that to you because you're the only one who has it.
Would a vendor solving this need three months of deep customization just to understand the situation? If yes, you're not really buying a product. You're paying premium consulting rates to teach a vendor how your business works, and then renting back the system you helped them build. That's a worse deal than building it yourself with a team that actually retains the knowledge.
If the answers point to proprietary, build. And invest properly. Proprietary AI systems built half-heartedly are the most common source of the failed projects we get called in to rescue.
Where Organizations Get It Wrong
The two failure modes look different but stem from the same framing error.
The first is buying what they should have built. A mid-market firm rolls out an off-the-shelf customer intelligence platform because it was faster and cheaper than building one. Two years later, the platform's outputs don't align with how their sales team actually qualifies opportunities, the vendor won't customize the model logic without an enterprise contract, and the organization quietly stops using the system. They've spent the equivalent of a small engineering team's salary on a product that gave them no advantage.
The second is building what they should have bought. An internal team spends a year building a generic document classification pipeline because nobody wanted to commit to a vendor. The system works adequately. It also costs three engineers a quarter every year to maintain, while a commercial product that does the same job better is available for a fraction of the loaded cost. The team has built infrastructure that doesn't differentiate the business and now owns it forever.
Both organizations did the work. Both spent the money. Neither got an advantage. The framing produced the wrong answer in both directions.
The Hybrid Case
Most real AI problems aren't purely generic or purely proprietary. They're a stack, and different layers of that stack have different answers.
A retrieval-augmented generation system over your proprietary documents is a classic example. The vector database is generic infrastructure, so buy it. The embedding model is largely generic, so use a strong off-the-shelf one. The retrieval logic and the way you chunk, score, and rerank against your specific corpus is proprietary, so build it. The orchestration and the production wrapper might be either, depending on your scale.
The pattern that works is to be ruthlessly precise about which layer is which. Buy the infrastructure. Build the IP layer. Don't conflate them, and don't let your engineering team's enthusiasm push you into building infrastructure or your CFO's caution push you into buying away your differentiator.
A Better Ownership / Boardroom Question
The next time the build-vs-buy conversation starts, replace it with a sharper one. "What's our edge here, and where exactly does it live in the stack?"
That question forces the strategic thinking that the cost-and-control frame avoids. It separates the parts of the system where ownership matters from the parts where it doesn't. It produces a clear architecture rather than a compromised middle position. And it tends to expose, very quickly, the cases where the team can't actually articulate where their edge is. That itself is useful information, because you shouldn't be building or buying anything until you can.
Build versus buy isn't an architectural argument. It's a strategic one. The teams that get this right are the ones that know which parts of their stack are differentiators and which parts are infrastructure, and who treat those two categories with the discipline they each deserve.
Why One Data Scientist Isn't Enough

AI increasingly demands a wide array of skills to cover the ground between idea, creation, implementation, deployment and scaling / monitoring.
You made the hire.
You found someone with the right credentials, the right experience, maybe even a graduate degree in machine learning. They were supposed to be the person who finally got your AI initiatives off the ground.
Six months in, nothing is in production. Your data scientist is buried in data cleaning, wrestling with infrastructure they weren't hired to manage, and building prototypes that never make it past a Jupyter notebook. They're not failing. They're doing exactly what one person can do when you hand them a five-person job.
The Myth of the Full-Stack Data Scientist
Somewhere along the way, the industry started treating "data scientist" as a catch-all title. The job descriptions tell the story: must know Python, SQL, TensorFlow, cloud architecture, data engineering, MLOps, statistical modeling, and stakeholder communication. Oh, and experience deploying production systems at scale.
That's not a job description. That's a department.
Building AI systems that work in production requires at least three distinct skill sets that rarely live in the same person: research and modeling, data engineering, and ML operations. Asking one hire to cover all three is like hiring a single person to be your architect, general contractor, and electrician. They might know something about all three, but the house isn't going to be built well.
What Actually Happens
It plays out the same way almost every time. The data scientist spends their first few months getting access to data, understanding the business context, and cleaning datasets that were never designed for machine learning. Necessary work, but it's data engineering work — and it eats months that leadership expected would be spent building models.
When they finally get to modeling, they build something promising in a notebook. It performs well on test data. The demo looks good. But then comes the question nobody planned for: how does this get into production?
Deploying a model means building APIs, setting up monitoring, handling versioning, managing retraining pipelines, and integrating with existing systems. These are software engineering and infrastructure problems. Your data scientist may be able to figure some of it out, but they're learning on the job, solving problems that a dedicated ML engineer would handle in a fraction of the time.
Meanwhile, leadership is wondering why the AI investment hasn't produced results.
The Isolation Factor
There's something else going on that doesn't get enough attention. A single data scientist working inside a non-technical organization is professionally isolated. No one to review their modeling choices. No one to debate architecture decisions with. No one who understands why the work is taking longer than the vendor demos suggested.
That isolation pushes toward two outcomes. Either the data scientist makes decisions in a vacuum and builds something that works technically but misses the business need, or they get so cautious about making wrong choices that progress grinds down. Both paths end the same way: leadership loses confidence, the data scientist gets frustrated, and they leave within 12 to 18 months. Then the cycle starts over.
What the Role Actually Requires
The organizations that successfully build AI capabilities in-house don't start with one hire. They start with clarity about what they're building and what skills that demands.
A production AI system needs someone who understands the data and can build reliable pipelines. It needs someone who can research, experiment, and select the right modeling approach. And it needs someone who can deploy, monitor, and maintain that model once it's running. In larger organizations, add a product manager who translates between the technical team and business stakeholders.
That doesn't mean you need four people on day one. But it does mean a single data scientist, no matter how talented, will hit a ceiling unless you've planned for the capabilities they need around them.
The Alternative to Hiring Your Way Out
For mid-market organizations that aren't ready to build a full AI team, the better path is often pairing internal knowledge with external depth. Your people understand the business, the data, and the problems worth solving. An external team with production experience can bring the engineering, architecture, and deployment expertise that turns a promising prototype into a working system.
This isn't about outsourcing your AI strategy. It's about being honest that building production AI requires a combination of skills that takes years to assemble internally. The organizations that get this right stop treating AI as a single hire and start treating it as a capability that needs a team — whether that team is fully internal, partially external, or somewhere in between.
The question isn't whether your data scientist is good enough. It's whether you've set them up to succeed.
Why Your AI Vendor's Demo Looked Great … and Their Delivery Didn't
Here are three main reasons this happens, and how to avoid it in the future.
You've seen it happen.
Maybe more than once.
A vendor walks into the room with a demo that does exactly what you need. The model works. The interface is clean. The use case maps perfectly to your business problem. Three months later, the project is stalled, the timeline has doubled, and the vendor is explaining why production is "more complex than expected."

You're not imagining things. The gap between demo and delivery is one of the most predictable failure patterns in AI projects. Understanding why it happens is the difference between choosing your next vendor wisely and repeating the same expensive lesson.
The Demo Is Designed to Impress, Not to Ship
The part nobody mentions during the sales process: a demo is a controlled environment. The data is curated. The edge cases are removed. The model is tuned to perform well on a narrow set of inputs that map perfectly to the story the vendor wants to tell.
None of that is dishonest, exactly. It's how demos work in every industry. But AI has a unique problem that makes the demo-to-production gap wider than most buyers realize.
In traditional software, what you see in a demo is roughly what you get. The interface might change, the features might shift, but the underlying mechanics are the same. In AI, the demo and the production system can be fundamentally different things. A model that performs at 95% accuracy on a curated dataset might drop to 70% on your real-world data. And 70% accuracy in production isn't a minor gap. It's the difference between a useful system and an expensive distraction.
Three Structural Reasons Demos Don't Translate
This isn't about bad vendors. Some of the firms that demo beautifully are genuinely talented teams. The problem is structural.
1. Your data isn't their data.
The demo ran on clean, well-labeled, representative data. Your data has gaps, inconsistencies, legacy formats, and domain-specific edge cases that nobody mentioned during the sales cycle because nobody asked the right questions. The vendor assumed your data would look like their training data. It doesn't. It never does.
This is where most projects hit their first real delay. The vendor scopes two weeks for data integration and spends two months discovering that your actual data environment looks nothing like what they planned for.
2. Production requirements were never part of the conversation.
A demo doesn't need to handle latency constraints, concurrent users, security requirements, system integrations, or graceful failure modes. Production does. These aren't minor implementation details. They're architectural decisions that should shape the entire system design from day one.
When a vendor builds the demo first and worries about production later, they're often building on a foundation that can't support what comes next. Retrofitting a demo into a production system is like renovating a house by starting with the wallpaper. At some point you have to deal with the plumbing, and by then, everything built on top is at risk.
3. The team that sold you isn't the team that builds it.
This one is particularly common with larger firms, but it happens at boutiques too. The senior architect who diagnosed your problem in the sales process hands off to a more junior team for delivery. That team is capable, but they weren't in the room when the nuances of your business were discussed. They're working from a scope document, not from understanding.
The result is technically competent work that misses the point. The model works. It just doesn't solve the problem you actually have.
What Buyers Miss During Evaluation
If you've been through this cycle, you might think the answer is better due diligence. Ask more questions. Check more references. That helps, but most evaluation processes focus on the wrong signals.
Buyers tend to evaluate what a vendor can build. The better question is how they build it.
Ask about their diagnostic process before any code is written. How do they assess whether your data can support the proposed solution? What happens when they discover it can't? Do they have a prototyping phase that uses your actual data, or do they go straight from demo to development? What does their team structure look like, and will the people in the room today be the people building tomorrow?
The answers to these questions tell you more than any demo ever will. A vendor who has a thoughtful diagnostic process, who builds with your real data early, and who keeps senior talent through delivery is structurally less likely to hit the demo-to-production wall. Their process is designed to surface problems before those problems become expensive.
The Diagnostic Step Most Vendors Skip
There's a phase that belongs between "this looks promising" and "let's build it" that most AI engagements skip entirely: an honest assessment of whether the proposed solution will work with your specific data, in your specific environment, for your specific use case.
This isn't a proof of concept. A POC is typically designed to prove the vendor's approach works. A diagnostic assessment is designed to find out whether it will. The difference matters. One is built to succeed. The other is built to tell the truth.
A proper diagnostic answers the questions that should have been asked before the contract was signed: Is the data sufficient? Is the problem well-framed? Are the success metrics aligned with what the business actually needs? What are the real risks, and what would mitigation look like?
When this step gets skipped, the entire project becomes the diagnostic. You're paying production prices for discovery work. By the time the real challenges surface, there's too much momentum and too much spend to change course easily.
Choosing Differently Next Time
If your last AI vendor delivered a great demo and a disappointing project, you're in good company. The pattern is common enough that it's become one of the primary reasons organizations develop AI skepticism. The problem isn't that AI doesn't work. It's that the way AI is sold doesn't match the way it needs to be built.
The organizations that break this cycle change how they buy. They insist on a diagnostic phase with real data before committing to a full build. They keep senior talent accountable through delivery, not just sales. And they ask the uncomfortable question early: what happens when this doesn't work as well as the demo?
The best time to ask that question is before you sign. The second best time is now.
Your AI Project Didn’t Work. Do You Know Why?
Consider the benefits of a third-party post-mortem. Seriously.

Cultivating resilience: New growth begins where the old lessons were learned.
Most organizations that walk away from a failed AI initiative make the same mistake twice: they move on without understanding what went wrong.
It's understandable. The project already cost time, money, and internal credibility. The last thing anyone wants is to spend more resources examining a failure. But that instinct, closing the chapter and moving on, is exactly what leads to the same problems showing up in the next attempt.
The Pattern We Keep Seeing
Here's what typically happens. An organization invests in an AI initiative. Maybe a recommendation engine, an internal knowledge system, or an automation pipeline. Six months in, the project stalls. The vendor blames the data. The internal team blames the vendor. Leadership pulls the plug and everyone agrees to "revisit AI next year."
When next year comes, a new vendor pitches a new approach. It sounds different enough to feel like a fresh start. But underneath, the same structural problems are waiting: unclear success criteria, underestimated data complexity, misalignment between what the business needs and what the technical team built.
This cycle is expensive. And it's avoidable.
Why Internal Reviews Fall Short
Some organizations do attempt a post-mortem after a failed AI project. But when the people who built it are the same people reviewing it, the analysis has natural blind spots.
This isn't about blame or competence. It's human nature. Teams that lived inside a project for months have assumptions baked so deeply into their thinking that they can't see them anymore. They know what they intended the architecture to do. They know why they made certain tradeoffs. What they can't see is where those intentions diverged from reality. They were too close to the work.
An internal review tends to surface symptoms: the model wasn't accurate enough, the data was messy, the timeline was too aggressive. Real observations, sure. But rarely root causes.
What an Independent Post-Mortem Actually Uncovers
An independent third party brings something no internal team can: fresh eyes with deep expertise and no attachment to the decisions that were already made.
A good AI post-mortem goes beyond "what happened." It answers three questions that actually matter for your next initiative:
1. Was this the right problem to solve with AI? Not everything that looks like an AI problem is one. Sometimes the real issue is a data pipeline problem, a process design problem, or something better solved with straightforward automation. An independent review can make this call without the sunk-cost bias that affects everyone who was involved in the original decision.
2. Where did the technical approach break down? AI projects fail for specific, diagnosable reasons. Was the training data representative of production conditions? Was the problem framed correctly for the chosen model architecture? Were the evaluation metrics aligned with actual business outcomes? Answering these requires genuine depth. A surface-level review produces surface-level answers.
3. What needs to be true for the next attempt to succeed? This is the question that makes the investment worthwhile. A post-mortem isn't an autopsy. It's a blueprint. What data needs to exist, and in what form? What does the team need to look like? What are the realistic milestones and decision points? An independent assessment can lay this out clearly because they're designing for what works, not defending what was already tried.
The Cost of Skipping This Step
Consider the math. If your failed AI initiative cost $200,000 (a conservative number for a mid-market project) and you start a new one without understanding why the first one failed, you're betting another $200,000 that the problems were circumstantial rather than structural.
Sometimes they are circumstantial. More often, they're not.
The research supports this. Industry data shows 42% of organizations abandoned most of their AI initiatives in 2025. The majority of generative AI pilots never reach production impact. These aren't isolated failures. They're patterns. And patterns have identifiable causes.
A post-mortem that costs a fraction of the original project can save you from repeating the full cost of failure. And it gives your team and your leadership something harder to quantify but just as valuable: confidence that the next initiative is built on solid ground, not optimism.
What to Look for in a Post-Mortem Partner
Not every consultant can do this well. Here's what matters:
Research-grade diagnostic ability. The person reviewing your project needs to understand AI systems at a fundamental level. Not just how to use tools, but why certain approaches fail under certain conditions. There's a real difference between someone who can identify that your model underperformed and someone who can tell you why it underperformed and what architectural decision caused it.
Cross-scale experience. AI fails differently at different organizational scales. Someone who's only worked with startups won't understand the integration challenges of enterprise systems. Someone who's only worked with Fortune 500 firms won't understand the resource constraints of a growing company. You want someone who's seen both ends.
Honesty over billable hours. The post-mortem partner should be willing to tell you that your next AI project shouldn't be an AI project at all. If the assessment is designed to generate follow-on work rather than genuine insight, that's not an assessment. It's a sales pitch.
Moving Forward
If your organization has shelved an AI initiative, or is watching one struggle right now, the worst thing you can do is nothing. The second worst is starting over without learning from what happened.
An independent post-mortem turns a failed investment into a clear path forward. It's a small step, but it changes the odds for everything that comes after.
You can afford the post-mortem. The question is whether you can afford to skip it.
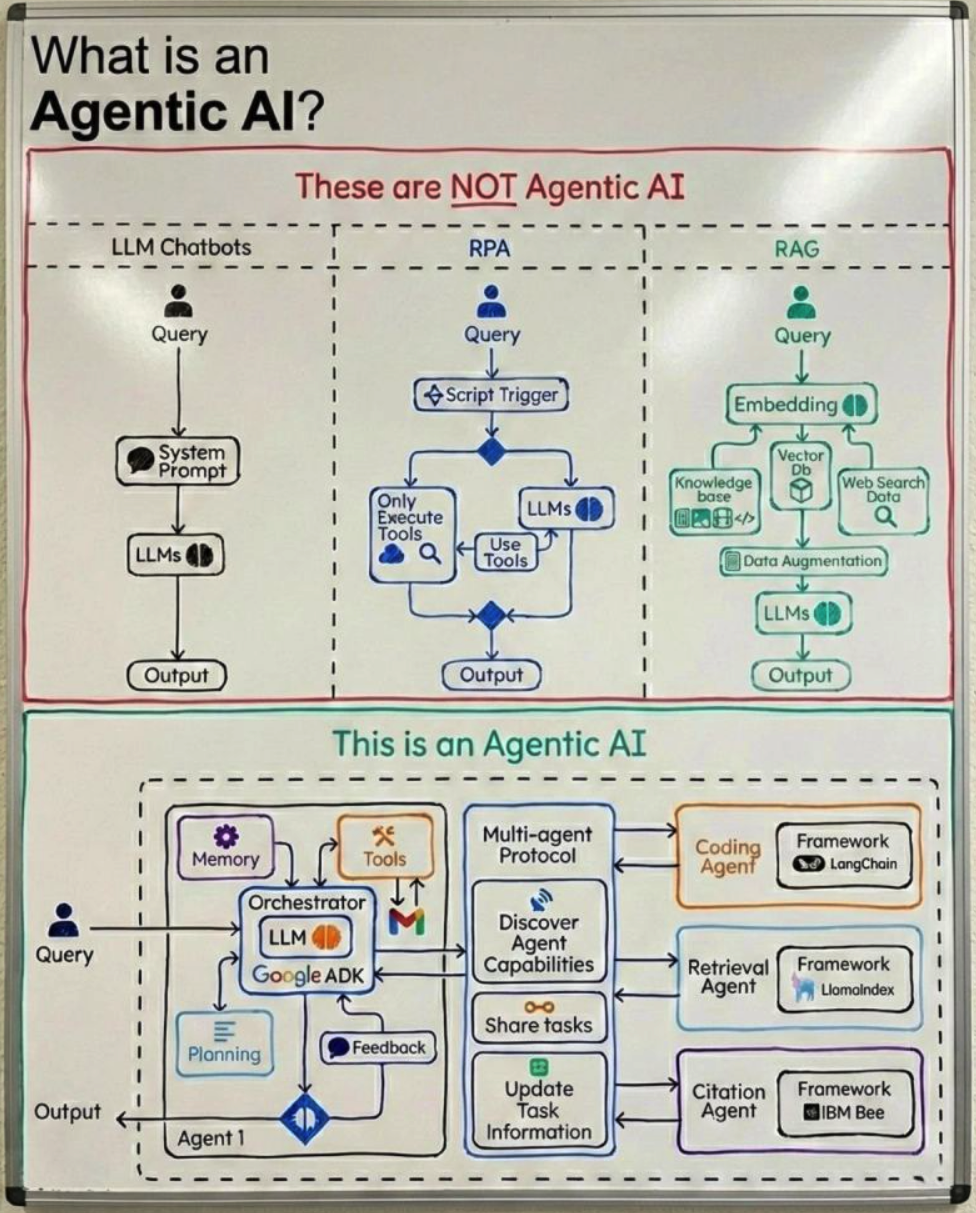
Agentic AI - defined by context?
A blog post by this group made a good stab at defining “Agentic AI” by, in part, describing both what it is and contrasting it with what it is not. A very useful framing, illustrated by the diagram below. Something to help me think about the potential of combining RAG principles with multi-step, complex work flow and problem solving it a useful way.
The Next Iteration of RAG ?
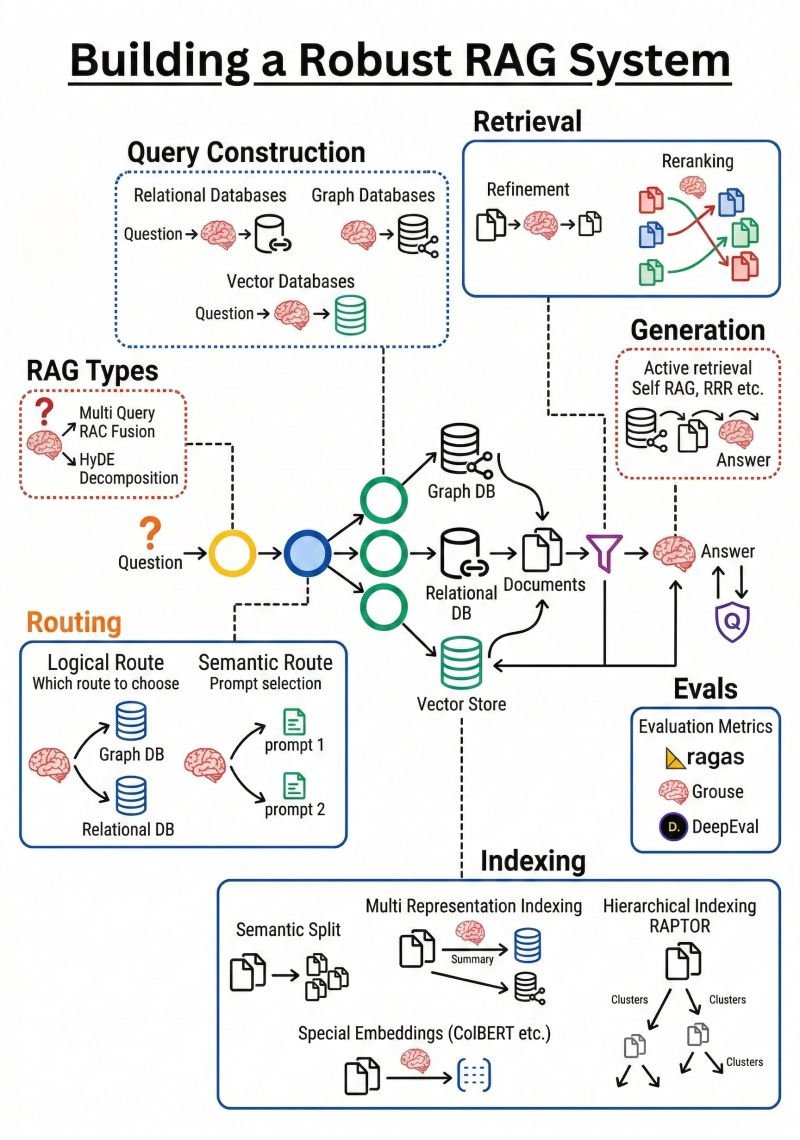
Every aspect of LLM-based solution development remains in flux, with architectures evolving rapidly toward paradigms of greater power and business relevance. Recently I have encountered compelling arguments for what next-generation RAG should look like. A post by Brij Kishore Pandey — something along the lines of "Stop doing RAG like it's 2023" — resonated strongly, as I recognized that several advances that might be helpful if incorporated into my own work.
———————————————————-
The boundary between RAG and agentic approaches is itself becoming harder to define as agentic methods grow in strength, reliability, and ease of use. That said, the core principle remains constant: assembling the right context is central to effective LLM-based solutions, regardless of the architectural pattern used.
———————————————————-
Before mapping out Cognosa 2.0, I intend to study the graphic from Kis' post carefully. I am not, however, convinced that a Swiss army knife architecture will ever represent the optimal solution for every use case. Having already implemented enhanced retrieval types with tunable parameters, flexible filtering, and customized semantic chunking, I question whether every element of the proposed architecture is necessary — or even beneficial — for my intended use cases. More study is warranted. That said, my experience with agents, Claude Code, and the composability of skills and sub-agents gives me good reason to engage seriously with this framework and extract what is most applicable. Balancing the utility of generalizability and the power of finely honed improvements for narrow or speceific use cases is a common trade-off for product managers; perhaps investment is best defined in the context of my next customer!
Experimenting with a new LLM: QWEN
We have established an Alibaba Cloud account to evaluate their model offerings. Initial impressions are consistent with expectations: their models trail the frontier but perform comparably to Llama 3.1 and similar large open-source models — perhaps six to twelve months behind the leading providers. This week I plan to run direct comparisons against our existing Cognosa use cases, which is straightforward given the platform's ability to route identical queries across models and compare outputs side by side.
I have reduced the frequency of these comparisons, however, for two reasons. First, my daily satisfaction with Claude continues to increase. Second, ongoing disappointment with OpenAI — not only in coding tasks but across technical domains including DNS, Docker Compose, and infrastructure troubleshooting — reduces my incentive to benchmark regularly. Gemini has emerged as my preferred backup assistant and likely outperforms ChatGPT in most of my workflows, though I continue to alternate between them. I have also discontinued running large open-source models locally on my Mac Studio: inference is too slow, output quality insufficient, and my API spend across frontier providers remains well below any meaningful optimization threshold — at least for now.
Semantic Chunking
Or, more simply: how smart, customized RAG solutions deliver better answers
It probably won’t surprise anyone that a consultancy focused on semantic technologies believes that semantic decomposition — or the more headline-friendly term semantic chunking — really matters. Whether you’re building a generative AI assistant or a more traditional analytics workflow, better decisions usually come down to having the right information at the right moment. That might mean real-time sensor data driving an automated process, or it might mean helping a human answer a detailed question about a product, regulation, or technical system. In either case, identifying the relevant context quickly and accurately is what makes the answer useful.
For small or tightly scoped knowledge bases, this isn’t hard. A simple chatbot can scan most or all of the available material and produce a reasonable response. But once you’re dealing with hundreds or thousands of pages — manuals, specifications, discussions, updates, and historical notes — brute-force approaches stop working. You can’t realistically pass all that material to an LLM every time, and retraining a custom model is expensive, slow, and often impractical when the data is changing.
This is exactly why Retrieval-Augmented Generation (RAG) has become so popular. Instead of training the model on everything, you retrieve just the most relevant context and use that to support generation. But this is also where many RAG systems start to struggle. If your documents are simply chopped into uniform blocks and indexed, the retrieved “chunks” can end up being a kind of word salad — loosely related text that looks relevant on the surface but doesn’t actually answer the question being asked.
That’s where semantic chunking comes in. On the Cognosa AI-as-a-Service platform, we load data in a way that tries to preserve meaning, not just token counts. The goal is to capture complete ideas — instructions, definitions, explanations, constraints — at a level of detail that makes sense for each source. A 300-page user manual needs to be handled very differently from a collection of recipes or short biographies. Product catalogs introduce their own challenges, especially when many items share similar attributes and options and the system must not mix them up.
You’ll often hear people talk about different “chunking strategies,” and a quick search will turn up plenty of debates about which approach is best. But when you step back, most of these discussions are really circling the same principle: keep meaningful, coherent information together, and don’t break associations that matter. The specifics vary by use case and data source, but the underlying goal is the same — make it easy for the system to retrieve context that actually helps answer the question.
There are, of course, many ways to implement this. You can describe semantic chunking in algorithmic terms, or focus on whether the parsing is done with LLMs, traditional NLP tools, rule-based approaches, or some hybrid of all three. Those choices matter for cost, performance, and reliability, but they’re ultimately tactical. The strategy is not “use an LLM” or “use a specific algorithm”; the strategy is to organize knowledge in a way that consistently supports high-quality answers.
In the real world, data is rarely neat or homogeneous. A collection of journal articles or a large email archive is about as simple as it gets. Most enterprise knowledge bases are far messier: user manuals, standards and regulations, technical specifications, customer correspondence, chat logs, spreadsheets, diagrams, tables, and scanned documents all mixed together. Making this usable requires organizing content based on what it means and how it relates to likely questions — not just where it appears in a file.
At CogWrite, we’ve built and refined RAG collections using a range of tools and techniques across many projects. We maintain a growing library of ingestion routines and have created vector databases for different types of domain-specific AI solutions. This allows us to adapt quickly while still tailoring the approach to the data and the problem at hand.
One example is our work around Casambi, an open-source, low-energy Bluetooth lighting control protocol. There’s a wealth of publicly available material about Casambi — documentation, specifications, guides, presentations, and discussions — but it exists in many formats and levels of detail. We built a Casambi document collection specifically to support a question-and-answer workflow, and it has become one of our internal testbeds for experimenting with more sophisticated semantic chunking techniques and retrieval strategies.
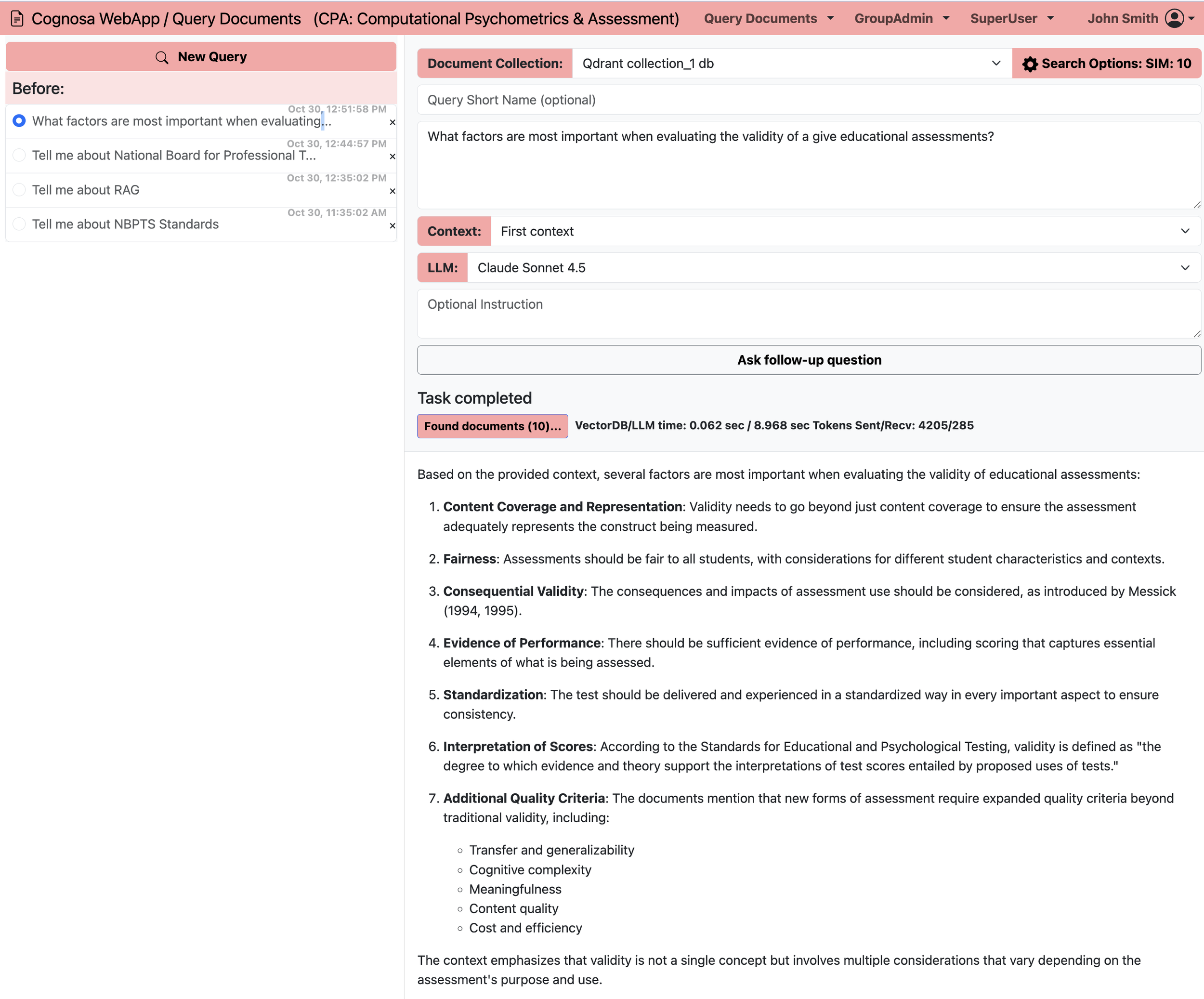
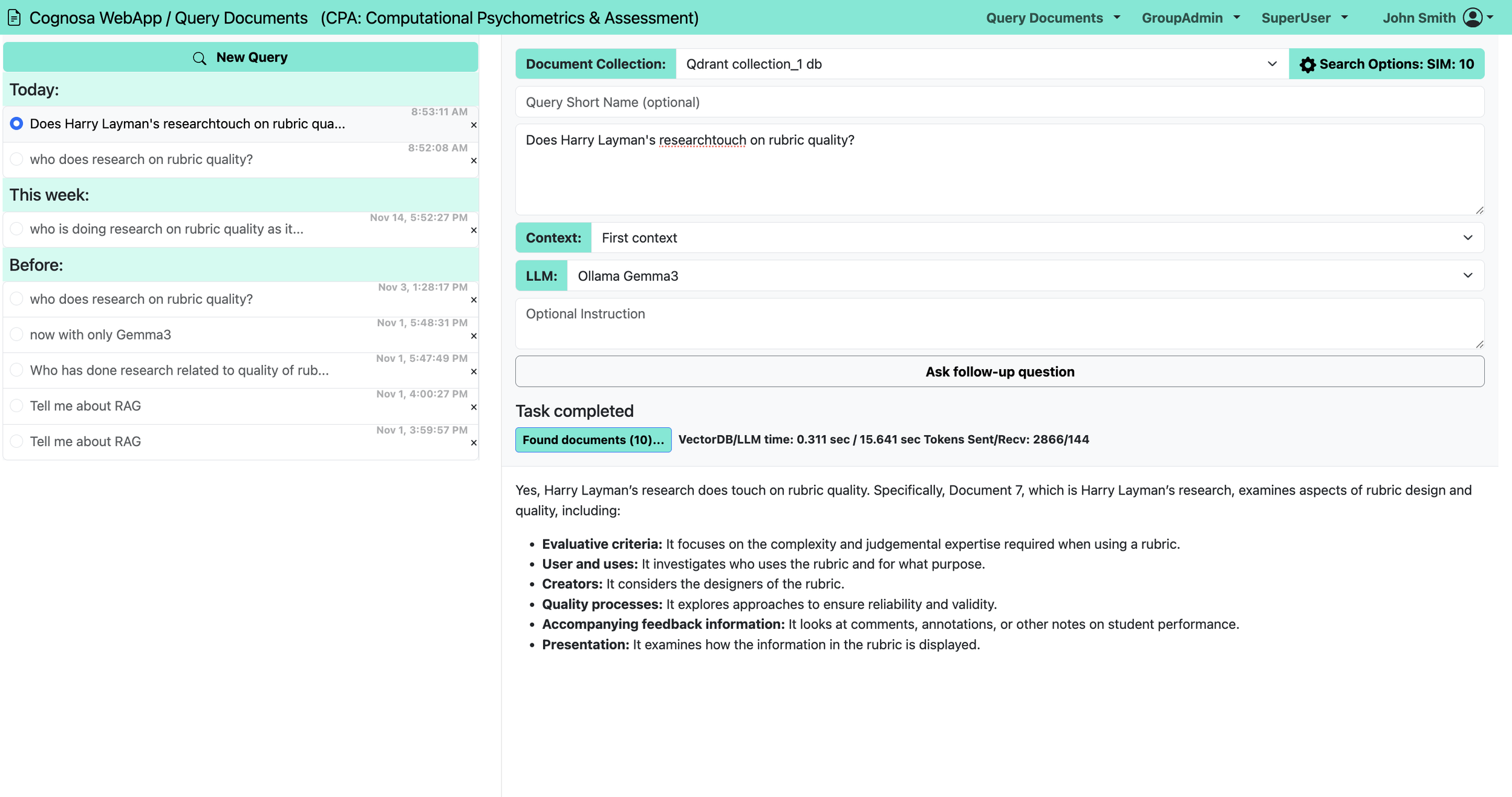
A sample query and response from that system is shown below.
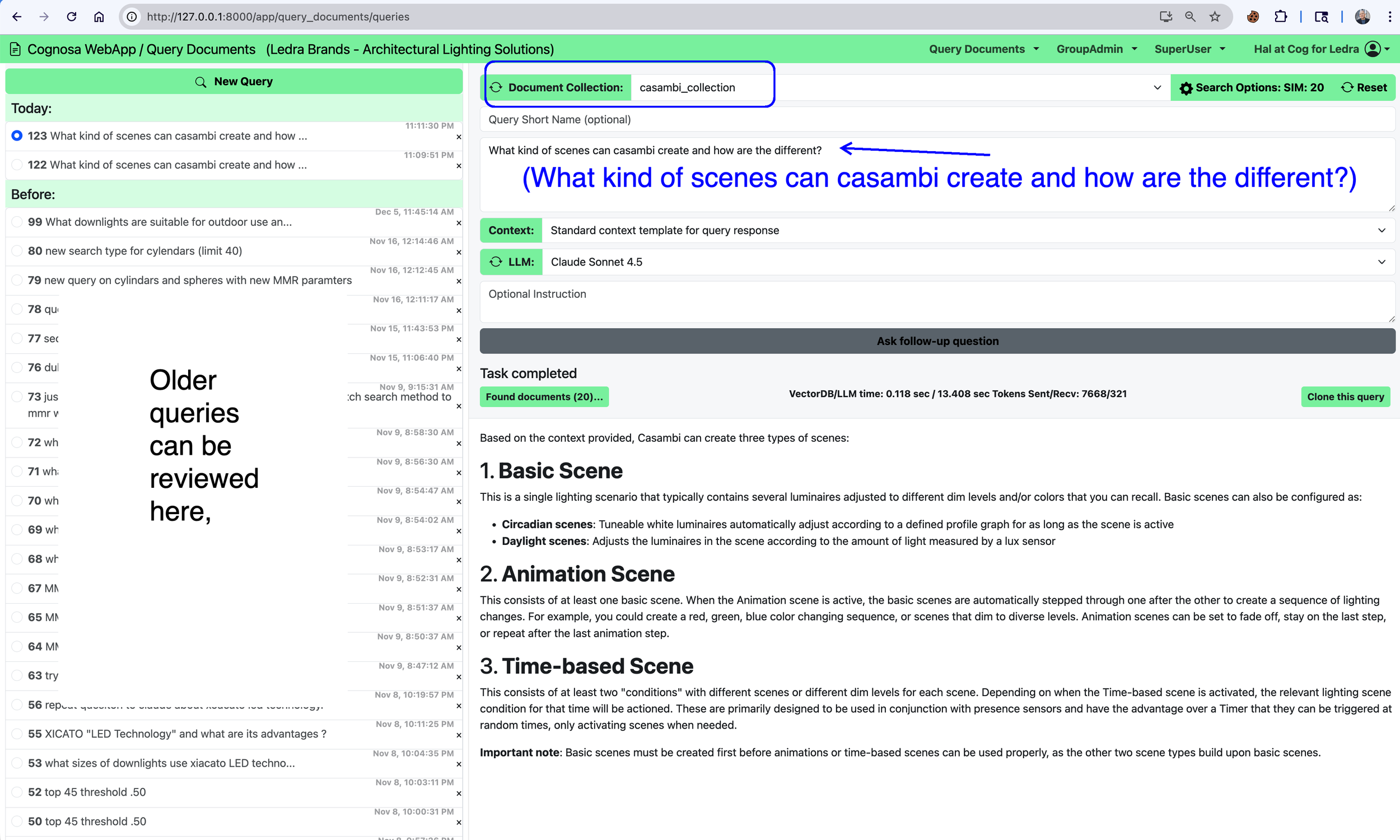
A simple query about a complext progocol implemented around the world for high quality industryial lighting control and management.
Cognosa Capabilities: LLM access options
Open Source or Proprietary Large Language Models
Queries With — or Without — Context
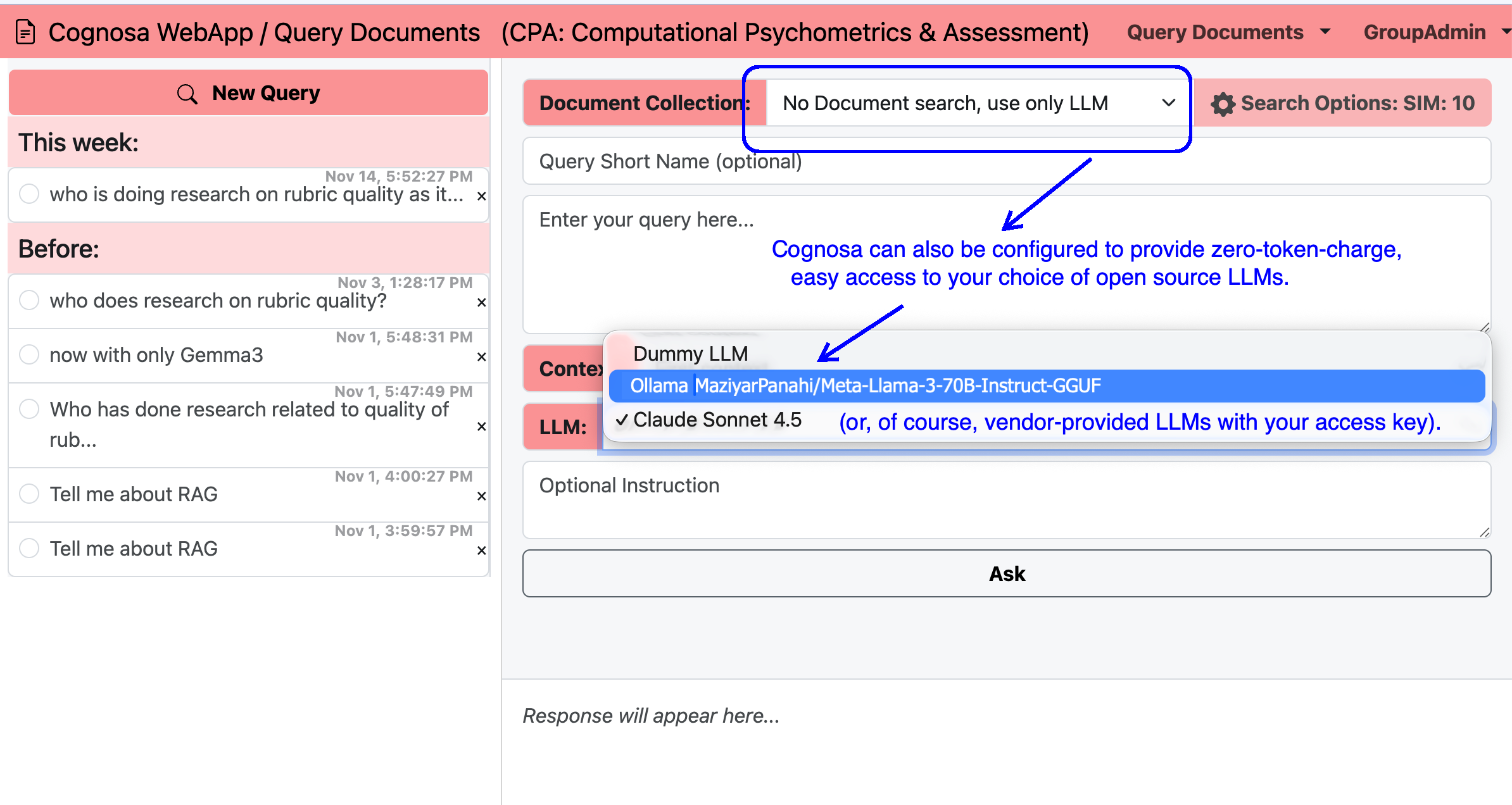
Cognosa supports two complementary ways of using AI. First, users can ask questions directly to a large language model, much like using a standard chatbot. Second—and far more powerful—users can query an LLM that is enhanced with organization‑specific data collections they are authorized to access. Both modes work with either free, open‑source models (no per‑token charges) or commercial models such as those from Anthropic or OpenAI, using the customer’s own API key.
Augmented Queries with Company Data
Organizations often maintain multiple data collections: industry research, regulatory guidance, internal policies, customer service resources, product documentation, and more. Cognosa can connect any or all of these collections to an LLM, giving users precise, context‑rich answers. In the example shown, this Cognosa workspace offers access to an open‑source Llama‑3 70B model (optimized for accuracy and speed) or Anthropic’s Claude 4.5 Sonnet model. Queries sent to Claude generate charges directly to the customer’s Claude API account, while Cognosa saves and logs all queries and responses for later review.
Illustrative Token Costs
As of this writing, Anthropic’s pricing for the Sonnet 4 family (200k‑token context window) is approximately:
• $3 per 1M input tokens
• $15 per 1M output tokens
A typical context‑augmented query may include about 3,000 input tokens (a short question plus relevant retrieved context) and return about 1,000 output tokens. At six such queries per workday, this usage comes to roughly 126.72 USD per month—regardless of whether it is one person making multiple queries or several users making fewer queries each.
By contrast, a direct LLM query (no contextual augmentation) might use only 450 tokens in and 350 tokens out, totaling an estimated 34.85 USD per month for the same number of daily queries.
Examples
The figures below shows how Cognosa displays both types of queries:
a) direct questions to an LLM, and
b) augmented questions answered using your organization’s specialized data collections.
Query without context:
Query with context: (1 of 3)


Query with context: (2 of 3)
Query with context: (3 of 3)


Cognosa solutions v. Custom GPTs
One reason we created the Cognosa platform was that while some customers had quick success using Custom GPTs in OpenAI’s ecosystem, over time they found that the no-code approach could not answer certain queries reliably, could not scale to support larger or more complex datasets, or became very expensive at higher usage levels.
This post compares OpenAI’s GPT Builder — how it works, what it does well, and where it differs from a purpose-built Retrieval-Augmented Generation (RAG) solution like Cognosa.
Setting the stage: Custom GPTs vs. a purpose-built RAG solution
Many organizations experimenting with AI start by testing Custom GPTs inside the OpenAI ecosystem. It’s an appealing option: upload some files, add instructions, and instantly get a conversational assistant that seems aware of your documents.
But the simplicity of a Custom GPT comes with inherent limitations. It offers convenience, not full control.
A purpose-built RAG solution — like the one Cognosa provides — takes a different approach. Your data, structure, semantics, indexing strategy, and retrieval logic become first-class components, giving you transparency, customization, and scalability that a generic builder cannot match.
Before jumping to the side-by-side comparison, it helps to understand what Custom GPTs actually do — and just as important, what they don’t.
What a Custom GPT Does Provide
Same base model, customized behavior
A Custom GPT uses the same underlying LLM that powers ChatGPT. You supply instructions and files, but you do not retrain or fine-tune the model’s weights.
Knowledge file uploads
You can upload PDFs, spreadsheets, or text files so the GPT can reference them during a conversation — e.g., “Use these spec sheets when answering product questions.”
Custom instructions
You define how the GPT should behave, how it should use its knowledge files, and what persona or style it should adopt.
Optional tools, actions, and APIs
You can enable external API calls, web browsing, or code execution to extend the assistant’s capabilities.
Internal retrieval from uploaded files
At runtime, the GPT can draw from your uploaded files for additional context. They serve as an internal reference set, not as training data.
No use of your data for public training
OpenAI states that Custom GPTs are not used to train or improve OpenAI’s public models
What a Custom GPT does not (or at least not clearly) do
It is not fine-tuning.
Uploading files does not train new model weights. The GPT uses your files as additional context, not as learned parameters.
It does not replace a full RAG architecture.
You cannot control chunking, embeddings, vector indexes, or retrieval pipelines. The internal mechanics aren’t exposed and may not resemble a traditional RAG pipeline.
It still inherits normal LLM limitations.
Hallucinations, context-window limits, and confusion between similar content can still occur without careful structuring.
It does not permanently embed your data
The GPT uses the base model’s tokenizer and inference engine. Your “knowledge files” act as temporary reference material, not integrated training data.
RAG vs Custom GPT — how they compare
Below is a side-by-side summary of how Cognosa’s RAG-first approach compares with OpenAI’s Custom GPT builder.
| Solution Area | Cognosa / RAG Approach | Custom GPT (OpenAI) |
|---|---|---|
| Data ingestion & indexing | Purpose-built vector database, tuned chunking, overlaps, similarity thresholds, and retrieval pipelines designed for your data and query patterns. | Upload files within limits; generic ingestion and chunking with minimal visibility or control. |
| Granular control over retrieval | Full control of embeddings, vector size, retrieval type, chunk size, and parameters. Tuned during customer validation. | Only files + instructions; embedding and retrieval logic remain opaque. |
| LLM usage | Use open-source or commercial LLMs; deploy in our cloud, your cloud, or on-prem. Open-source avoids per-token fees. | Tied to OpenAI’s API pricing; enterprise costs can be significant. |
| Model fine-tuning | Optional fine-tuning of open-source models; or use smaller models when retrieval matters more than reasoning. | No fine-tuning; behavior controlled only through prompts and context. |
| Latency & maintenance | Performance based on chosen infra; small 24×7 workloads run for low hundreds/month. | Minimal ops overhead; OpenAI manages everything. |
| Traceability & control | Transparent retrieval with logs, auditing, and explicit control over data access. | Opaque retrieval; limited insight into contributing content. |
| Setup speed | RAG is complex to build alone, but Cognosa provides a turnkey managed setup. | Very fast: upload files + instructions and begin testing. |
| Operational cost | Predictable: setup + monthly cost based on hosting, model, and usage. | Ongoing OpenAI token charges; low barrier to start, expensive at scale. |
Next time, we’ll take an advanced look at some of how this magic works: the actual UI that gives advanced users access to alternative retrieval strategies and parameters!
Cognosa in the Spotlight: Why AI-as-a-Service Might Be Right for Your Business
It all begins with an idea.
Intro
Every few years, a technology shift quietly changes how work gets done.
AI-driven automation—especially Retrieval-Augmented Generation (RAG)—is one of those shifts. Yet many organizations aren’t benefiting from it. Not because the technology isn’t ready, but because their own data isn’t being used to make AI truly useful.
That’s the gap CogWrite Semantic Technologies built Cognosa to close.
Welcome to Cognosa in the Spotlight, a new blog series that explains AI-as-a-Service in practical, business-friendly terms—and shows how Cognosa will soon help small and mid-sized organizations put their own knowledge to work.
Why generic AI isn’t enough for real business tasks
ChatGPT-style assistants are impressive, but they do not:
know your company policies
know your products or parts inventory
understand your compliance rules
reflect your training materials
capture years of institutional knowledge or workflows
Without your specialized data, a general-purpose model can only give general-purpose answers.
What changes everything is AI that’s augmented with your private, domain-specific knowledge.
The power of AI + your proprietary data (RAG)
Retrieval-Augmented Generation (RAG) lets an AI system draw on your actual documents, procedures, manuals, specifications, and knowledge bases—while keeping that data private and secure.
This unlocks practical, high-value use cases such as:
Customer service augmentation – Answer customer questions from your real documentation, accurately, 24/7.
Compliance guidance – Give staff precise, policy-correct answers in regulated environments.
Technical support & troubleshooting – Integrate repair manuals, parts catalogs, service history, and SOPs.
Employee onboarding & training – Help new hires ramp faster with an “expert in chat form.”
Knowledge management & internal search – Replace clunky portals with natural-language answers.
In short: RAG turns your company’s documents into an always-available expert.
Why “AI-as-a-Service” matters
Most businesses don’t want to build and maintain their own:
vector databases
embedding pipelines
content “chunking” and indexing
API orchestration layers
prompt templates
monitoring and feedback loops
They do want the benefits.
AI-as-a-Service means you get the capability without the infrastructure, engineering overhead, or specialized in-house team. Cognosa’s mission is to make this accessible, reliable, and turnkey.
Where Cognosa is today—and what this blog will cover
CogWrite Semantic Technologies is approximately two months away from onboarding new beta users for Cognosa, our AI-as-a-Service platform.
Over the coming weeks, Cognosa in the Spotlight will explore:
what problems AI can realistically solve
how RAG works under the hood
how businesses can prepare their data
where AI provides immediate ROI—and where caution is warranted
practical examples of real-world solutions
how small and medium-sized teams can deploy AI effectively
Our goal is simple:
Help you identify the points in your workflow where an AI assistant—enhanced with your proprietary knowledge—can save time, reduce cost, and improve accuracy.
In future posts, we’ll walk through real-world solutions made possible by platforms like Cognosa and show how they can be implemented cost-effectively—without spending hundreds of thousands of dollars or paying $15,000/month for enterprise LLM access.